The problem with atomic CSS
When I published MaintainableCSS, I compared semantic and non-semantic class names.
In response, atomic CSS advocates critiqued semantic class names. While this got me thinking, my mind remains mostly unchanged.
Here I’ll explain why that is and address some of the responses.
1. “Semantic is a misleading word”
In Understanding Semantics, Léonie Watson says that semantic means:
“of code intended to reflect structure and meaning.”
This is why “wrapper” is semantic. It’s an element that wraps another, always. Whether CSS clears floated “columns” on big screens or stacks them on small screens, it’s always a wrapper.
Therefore once HTML is written, it doesn’t need to change. Where as a class of red, or clearfix is not semantic — at least not in the context of HTML.
In the context of HTML, a semantic class name describes what it is, not what it looks like or how it behaves.
2. “Semantic classes create sites that are slow to load”
I’ve built many sites. They were never slow because we used semantic class names. One recent example of this is a fully custom, fussy and responsive e-commerce site which totalled just 48kb.
It’s not slow and I didn’t pay much attention to CSS performance. We could make some savings but the current 48kb of CSS isn’t hurting anyone.
3. “Atomic CSS ensures design is consistent”
Theoritically, if you can only use predefined classes, it’s easier to ensure the UI is consistent. This makes sense because it limits what the developer can use. But there’s nothing to stop someone adding a new margin-bottom class or using the wrong one.
Perhaps there’s an opportunity to create a tool as opposed to a naming convention for this?
4. Analysing CSS performance in isolation
The most celebrated aspect of atomic CSS is that it results in a small CSS footprint which speeds up the time to first paint. The problem is that this point is always discussed in isolation making this selling point misleading at best.
Firstly, the size of the HTML increases a lot. Remember CSS is cacheable and serves an entire site like the one I mentioned earlier. HTML is unique, dynamic, and often personalised. It can’t be cached.
Secondly, the amount of CSS saved, even with large codebases, would be relatively small. While there may be sites with ten trigabytes of CSS, not only are they rare, there are solutions for this too.
Finally, the size of CSS is not the only performance indicator. Others need to be considered holistically.
5. Atomic classes are hard to read
Atomic class names are usually abbreviated. Abbreviations are hard to read. They have to be understood and mentally mapped. We should strive for clarity over brevity.
What does ‘blk’ mean, for example? Does it mean black or block? Let’s say it means black. Is that black text or a black background.
We can use verbose names that are easier to read, but this makes the HTML bigger and degrades performance — which is the reason for abbreviations in the first place.
And it shouldn’t be about saving keystrokes – text editors have autocomplete for this.
6. Atomic CSS recreates CSS in HTML
Atomic CSS recreates the same constructs found in CSS in order to use classes in HTML. CSS was designed for styling.
It’s wasteful recreating a convention for HTML which encourages developers to use the wrong tool for the job.
7. We need semantic class names anyway
In order to write functional tests and enhance websites with JavaScript we’re going to need semantic classes. So there’s going to be a mix of classes reserved for different things.
Inconsistent code is hard to reason about and if there are two ways of doing something, inevitably they’ll get mixed up.
8. Semantic CSS doesn’t violate ‘Don’t repeat yourself’ DRY
Trying to reuse a CSS rule is like trying to reuse a variable across different Javascript objects. It’s simply not in violation of DRY. CSS abstracted all the rules for us so that we can specify what we want when we want.
9. Semantic class names are easier to delete
A semantically-defined component is easy to delete because the related CSS is explicitly connected.
Whereas Atomic CSS is intertwined across a multitude of elements making the code hard to delete.
Before deleting the related CSS you need to look at each class on every element within the component, to determine if it’s used elsewhere. Only then can you decide if you can delete it.
Good code is easy to delete because it’s not intertwined.
10. Atomic CSS is a responsive design anti-pattern
As Ben Frain says in Atomic CSS is a Responsive Design Anti Pattern ‘making very specific changes at certain breakpoints and tying them to a class that has to be added to the HTML seems needlessly complex.’
He continues to say that ‘you inevitably end up with a raft of classes in your stylesheets that are obsolete.’ I agree.
11. It’s harder to style pseudo classes
For each style you want to change, you need an equivalent, verbose, hard to read class name. For example .red-text-when-hover or .black-bg-when-focus.
If the styles need to change at different breakpoints, it’s even harder. For example .red-text-when-hover-on-large-screens.
12. It’s harder to style based on state
Consider a basket that has an empty state. Each style that is different due to the state needs its own class.
13. Javascript now needs to manage styles too
JavaScript has to change several classes in response to a change of state.
For example, let’s say we have the following HTML:
<div class=”red-text float-left border-1px border-color-red”>
When the user clicks the <div> JavaScript needs to make sure the border becomes 2px thick and blue in colour.
Here you’d need to add (and maybe remove) several style declarations using JavaScript. Meaning that Javascript has to be “style aware” too.
14. It’s harder to style based on reading direction
As David Mark said on Twitter, ‘invariably, “pull-left” contains float:right in RTL configurations. That’s a clue as to why it makes no sense.’
15. It’s harder to enhance
If we want to use @supports we would need a .supports-x-do-y-class-name.
16. It’s harder to change layout mechanisms
As Ben Frain says in the same article ‘suppose […] we change our product […] from float based layouts to Flexbox based layouts. We now have twice the maintenance burden.’
17. It’s harder to fix Internet Explorer issues
Sometimes we add conditional CSS to fix Internet Explorer bugs. We can’t target atomic class names to do this.
18. Atomic classes are misleading and redundant
For example, overflow-hidden is used to clear floated children. However, in small screens the children are stacked, not floated. This is misleading for developers and redundant for users.
19. Every element needs classes
With atomic CSS every element needs several classes. But sometimes we don’t need to add a hook, as we can do this: .blah div or this: input[type=submit].
Also, Markdown, for example, forces us to style elements through a common ancestor with a semantic class name.
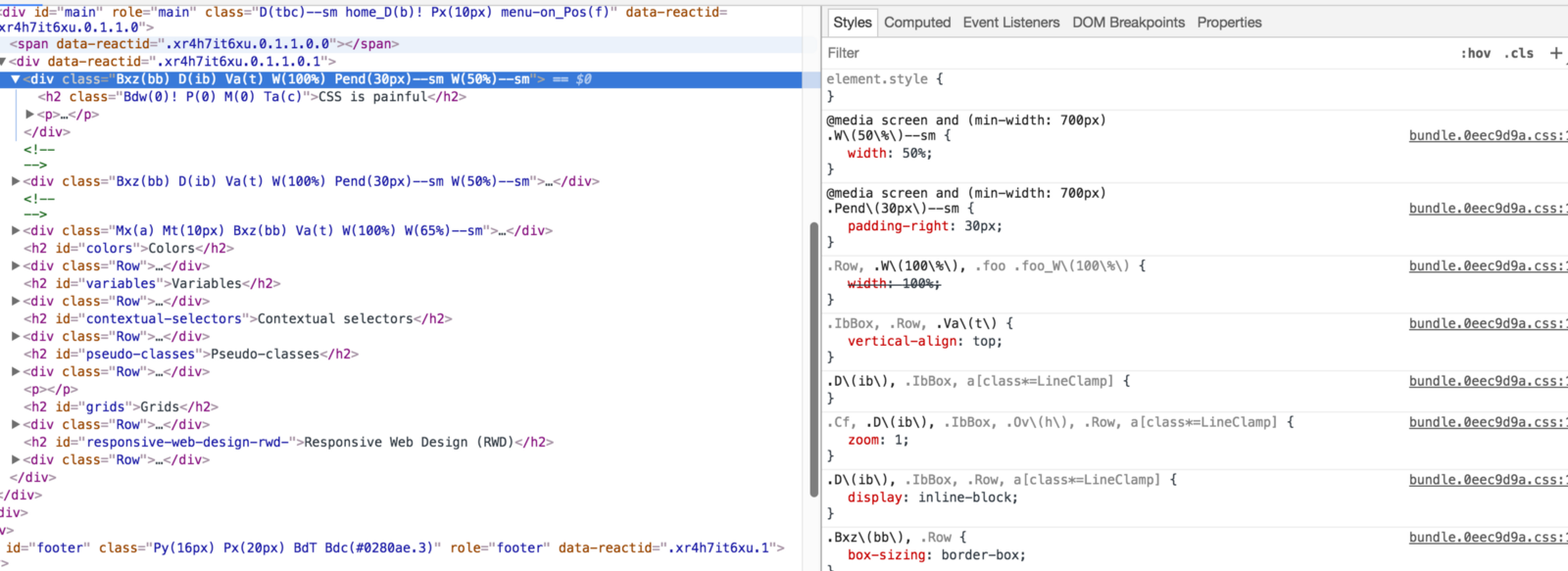
20. It makes the inspector noisy
It’s hard to work out where a component starts and ends because there’s nothing to demarcate it in the HTML. The content is obfuscated and the inspector has more lines of code to look at.
21. It’s hard to find HTML
It’s harder to search the codebase for a particular element because atomic class names aren’t unique to particular elements. While good file structure and templating helps, having to rely on it is less than ideal.
22. “Switching between HTML and CSS is hard”
Of all the things developers habve to do, pressing CMD+TAB is hardly taxing. And in reality, the only way you won’t have to switch to the CSS file (or documentation) is if you memorise every available class name.
23. “Atomic CSS makes it easy to reuse CSS across projects”
Being able to reuse CSS across projects is a nice idea if your sites are going to look the same. But most sites are branded uniquely to look different.
24. It’s hard to theme CSS
When I worked on a white-label solution for several e-commerce sites it was the HTML that was reused, not the CSS. That’s because the HTML is similar, not the CSS.
25. “Semantic classes are longer than atomic class names”
Here’s a typical snippet of atomic CSS from a site that has basic styling:
<div class="w5 w6-m w-50-l center overflow-visible mt3 mt4-m dtc-l v-mid-l tr-l">
I’ve never seen a semantic class name that is close to this.
Summary
In many cases, atomic CSS will decrease the size of your CSS file. That’s to be expected. Just like if I decided to inline all styles, I would expect the size of the CSS file to be zero.
The problem is that this introduces other issues that shouldn’t be ignored. Performance is only an issue once it becomes an issue. There could be many factors to consider.
I’m not saying to wait for a problem, but I’m not saying we should discard tried, tested and technology-embracing techniques like semantic CSS either.
There are other ways of making websites load faster with regards to CSS. For example, we don’t have to load the entire site’s CSS at once. We could load page-specific CSS and cache progressively.
Focusing on CSS isn’t necessarily where our energy is best spent. Perhaps the page has too much stuff. Perhaps the visual design is wasteful and not a benefit to users. You might be using a framework, CSS or otherwise which you don’t need.
All in all, having to navigate our way through all the trade-offs to shave some CSS, which drastically increases the size of HTML, is just trading one problem for several other bigger problems.
In most cases, we’re going to need semantic classes to do the job regardless. We may as well make use of them for CSS too.